
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- @Transactional Propagation
- Stream
- 자바 ORM 표준 JPA 프로그래밍
- multipart테스트
- javascript case
- 백명석님
- java
- HandlerMethodArgumentResolver
- #docker compose
- 마이크로 서비스
- intellij 핵심 단축키
- findTopBy
- @TransactionalEventListener
- IntelliJ
- 원격 브랜 삭제
- 리눅스
- ksql
- CompletableFuture
- aws
- Spring Cloud Netflix
- vue.js
- intellij favorites
- intellij 즐겨찾기
- 친절한 SQL 튜닝
- ksqldb
- Linux
- git
- 리팩토링 2판
- 자바 ORM 표준 JPA 프로그래밍 정리
- JPA
- Today
- Total
시그마 삽질==six 시그마
[우아한테크세미나 정리] 191121 우아한레디스 by 강대명님 (redis) 본문
[우아한테크세미나] 191121 우아한레디스 by 강대명님
https://www.youtube.com/watch?v=mPB2CZiAkKM
Redis 소개
● In-Memory Data Structure Store
● Open Source(BSD 3 License)
● Support data structures
○ Strings, set, sorted-set, hashes, list
○ Hyperloglog, bitmap, geospatial index
○ Stream
● Only 1 Committer
Redis 운영
● 메모리 관리를 잘하자.
● O(N) 관련 명령어는 주의하자.
● Replication
● 권장 설정 Tip
cache?
나중에 요청올 결과를 미리 저장해두었다가 빠르게 서비스 해주는것을 의미
팩토리얼 20880! 계산해 두고 어딘가 저장해 뒀다면 20881! 계산은 금방
core->L1 cache->L2 cache->L3 cache -> Memory(redis) ->Disk
오른쪽으로 갈 수록 용량은 커지나 속도(Latency)는 떨어짐.
파레토 법칙: 전체 요청의80%는 20%의 사용자가 한다.
cache 구조 1 look aside cache

cache 구조 2 write back
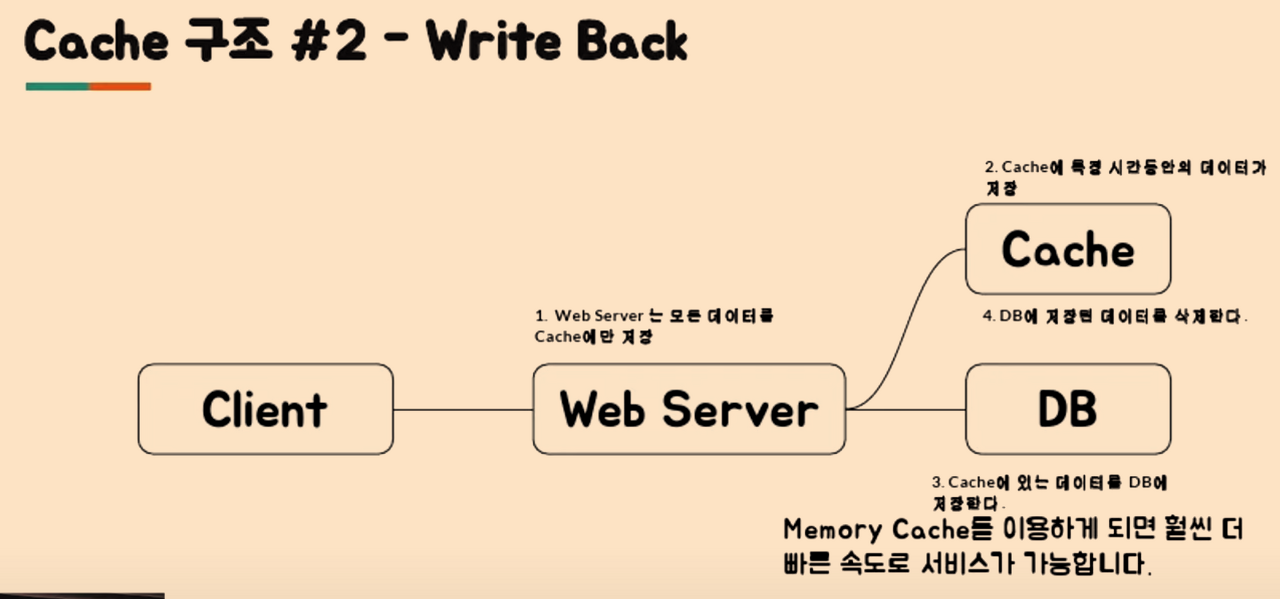
web server ->cache ->db
1) 로그 DB 저장시 사용
2) 해비한 write는 이렇게 쓴다.
3) 단점 :사라질 위험 있다.
왜 Collection 이 중요한가?
● 개발의 편의성
● 개발의 난이도
memCache는 collection 제공 안함
redis는 collection 제공함
랭킹 서버를 직접 구현한다면??
가장 쉬운방법
DB에 유저의 Score를 저장하고 Score로 order By 로 정렬 후 읽어오기
개수가 많아지면 속도에 문제가 발생할 수 있음(디스크를 사용하므로)
In-memory 기준으로 랭킹 서버의 구현이 필요함
Redis의 Sorted Set을 이용하면 랭킹을 구현할 수 있음
덤으로 Replication도 가능
다만 가져다 쓰면 거기의 한계에 종속적이 됨
랭킹이 저장해야할 id가 1개당 100byte라고 했을때
10명 1K, 1천만 1g
https://comart.io/blog/realtime-ranking-with-redis-sorted-set
https://jupiny.com/2020/03/28/redis-sorted-set/
ex)대기열 -Sorted Set
이벤트 주문을 요청한 순서대로 처리
ZADD key score member
>>ZADD - 데이터 추가시 부여한 스코어에 따라 정렬( 요청이 들어온 타임스탬프를 스코어로 부여)
>> ZADD key(redis key) score(value) member(key)
https://redis.io/commands/zadd/
http://redisgate.kr/redis/command/zsets.php
대기중인 사용자에게 현재 대기순번을 제공
ZRANK key member
>>ZRANK - 현재 순위 조회
일정한 수만큼 대기열 -> 참가열 이동
ZRANGE key start stop
>> ZRANGE-일정한 수만큼 리스트 조회
친구리스트 key/value 형태로 저장해야 한다면...
A있는 상태에서 두개의 독립적 작업T1(친구B추가) T2(친구 C추가)
A,B,C 가 아니라 A,B A,C 가 될 수 있다.
경쟁상태(Race Condition)
둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 공유자원에 동시에 접근하여 결과값에 영향을 줄 수 있는 상태
공유 데이터(잔고)에 최종값을 보장할 수 없는 상황
경쟁상태로 생기는 영역이임계구역(Critical Section)
임계구역을 해결하는 방법이 동기화 메커니즘(ex. 세마포어)을 사용
Redis의 경우는 자료구조가 Atomic 하기 때문에 해당 Race Condition을 피할 수 있다.
그래도 잘못짜면 발생함 (마우스 따닥이. wirte request 2번가는거)
왜 Collection 이 중요한가?
외부의 collection을 잘 이용하는 것으로 여러가지 개발 시간 단축시키고 문제를 줄요줄 수 있기때문에 collection 이 중요
Redis 사용처
● Remote Data Store
A서버, B서버, C서버에서 데이터를 공유하고 싶을때
● 한대에서만 필요한다면, 전역 변수를 쓰면 되지 않을까?
Redis 자체가 Atomic을 보자해준다(싱글 스레드라..)
● 주로 많이 쓰는 곳들
인증 토큰 등을 저장(Strings 또는 hash)
Ranking 보드로 사용(Sorted Set)
유저 API Limit
잡류(list)
Redis Collections
● Strings
제일 많이 쓰임
ex) Set token:1234567 abafdfdsfsdf , Set email:charsyam charsyam@naver.com
ex) MSet token:1234567 abafdfdsfsdf email:charsyam charsyam@naver.com
prefix는 값의 의미가 무엇인지 구분하기 위함인데 맨앞,맨뒤에 붙일 수 있는데 분산이 바뀔 수 있음.
● List
Lpush ,Rpush, Lpop, Rpop
● Set
SADD <Key> <Value>
SMEMBERS <Key> (모든 value 가져오는거 주의!)
SISMEMBER <Key> <Value> (value가 존재하면 1, 없으면 0)
특정 유저의 follower 리스트
● Sorted Set
제일 많이 쓰임
ZADD <key> <Score> <value>
Zrange <key> <StartIndex> <EndIndex>
Zrange <key> 0 -1 (모든 범위를 가져옴)
유저 랭킹 보드로 사용할 수 있음
sore는 double 타입이기때문에 값이 정확하지 않을 수 있다.
zrange key start stop
zrevrange key start stop
● Hash
Hmset <key> <subke1> <value1> <subkey2> <value2>
Hgetall <key> 해당 key의 모든 subkey와 value를 가져옴
Hget <key> <subkey>
Hmget <key> <subkey1> <subkey2> ...<subkeyN>
insert into users(name, email) values ('charsyam', 'charsyam@naver.com');
hmset charsyam name charsyam email charsyam@naver.com
Collection 주의사항
● 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않음
10,000개 이하 몇천개 수준으로 유지하는게 좋음
● Expire는 Collection의 item 개별로 걸리지 않고 전체 Collection에 대해서만 걸림
즉 해당 10,000개의 아이템을 가진 Collection에 expire가 걸려있다면 그 시간 후에 10,000개의 아이템이 모두 삭제
Redis 운영
메모리 관리를 잘하자
메모리 관리
● Redis 는 In-Memory Data Store.
● Physical Memory 이상을 사용하면 문제가 발생
○ Swap 이 있다면 Swap 사용으로(디스크 사용) 해당 메모리 Page
접근시 마다 늦어짐.
○ Swap이 없다면?
● Maxmemory를 설정하더라도 이보다 더 사용할 가능성이 큼.
● RSS 값을 모니터링 해야함.
많은 업체가 현재 메모리를 사용해서 Swap을 쓰고 있다는 것을 모를때가 많음.
큰 메모리를 사용하는 한 인스턴스 보단 작은 메모리를 사용하는 인스턴스가 더 안전하다.
(24g < 8g *3 , heavy한 write할때 인스턴스 메모리의 2배까지 사용할 수 있기에)
● Redis는 메모리 파편화가 발생할 수 있음. 4.x 대 부터 메모리
파현화를 줄이도록 jemlloc에 힌트를 주는 기능이 들어갔으나,
jemalloc 버전에 따라서 다르게 동작할 수 있음.
● 3.x대 버전의 경우
○ 실제 used memory는 2GB로 보고가 되지만 11GB의
RSS를 사용하는 경우가 자주 발생
● 다양한 사이즈를 가지는 데이터 보다는 유사한 크기의 데이터를
가지는 경우가 유리.
메모리가 부족할 때는?
● Cache is Cash!!!
○ 좀 더 메모리 많은 장비로 Migration.
○ 메모리가 빡빡하면 Migration 중에 문제가 발생할수도…
● 있는 데이터 줄이기.
○ 데이터를 일정 수준에서만 사용하도록 특정 데이터를 줄임.
○ 다만 이미 Swap을 사용중이라면, 프로세스를 재시작
해야함
메모리를 줄이기 위한 설정
● 기본적으로 Collection 들은 다음과 같은 자료구조를 사용
○ Hash -> HashTable을 하나 더 사용
○ Sorted Set -> Skiplist와 HashTable을 이용.
○ Set -> HashTable 사용
○ 해당 자료구조들은 메모리를 많이 사용함.
● Ziplist 를 이용하자.(속도는 느리지만 메모리 적게씀)
Ziplist 구조
● In-Memory 특성 상, 적은 개수라면 선형 탐색을 하더라도
빠르다.
● List, hash, sorted set 등을 ziplist로 대체해서 처리를 하는
설정이 존재
○ hash-max-ziplist-entries, hash-max-ziplist-value
○ list-max-ziplist-size, list-max-ziplist-value
○ zset-max-ziplist-entries, zset-max-ziplist-value
O(N) 관련 명령어는 주의하자.
● Redis 는 Single Threaded.
○ 그러면 Redis가 동시에 여러 개의 명령을 처리할 수
있을까?
○ 참고로 단순한 get/set의 경우, 초당 10만 TPS 이상
가능(CPU속도에 영향을 받습니다.)
● 한번에 하나의 명령만 수행 가능
○ 그럼 긴 시간이 필요한 명령을 수행하면?
대표적인 O(N) 명령들
● KEYS
● FLUSHALL, FLUSHDB
● Delete Collections
● Get All Collections
대표적인 실수 사례
● Key가 백만개 이상인데 확인을 위해 KEYS 명령을 사용하는
경우
○ 모니터링 스크립트가 일초에 한번씩 keys를 호출하는
경우도...
● 아이템이 몇만개 든 hash, sorted set, set에서 모든
데이터를 가져오는 경우
● 예전의 Spring security oauth RedisTokenStore
KEYS 는 어떻게 대체할 것인가?
● scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러번의
명령으로 바꿀 수 있다
Collection의 모든 item을 가져와야 할 때?
● Collection의 일부만 가져오거나…
○ Sorted Set
● 큰 Collection을 작은 여러개의 Collection으로 나눠서 저장
○ Userranks -> Userrank1, Userrank2, Userrank3
○ 하나당 몇천개 안쪽으로 저장하는게 좋음.
Redis Replication
● Async Replication
○ Replication Lag 이 발생할 수 있다.
● “Replicaof’(>= 5.0.0) or ‘slaveof’ 명령으로 설정 가능
○ Replicaof hostname port
● DBMS로 보면 statement replication가 유사
Redis Replication 시 주의할 점
● 많은 대수의 Redis 서버가 Replica를 두고 있다면
○ 네트웍 이슈나, 사람의 작업으로 동시에 replication이
재시도 되도록 하면 문제가 발생할 수 있음.
○ ex) 같은 네트웍안에서 30GB를 쓰는 Redis Master
100대 정도가 리플리케이션을 동시에 재시작하면 어떤 일이
벌어질 수 있을까?
redis.conf 권장 설정 Tip
● Maxclient 설정 50000
● RDB/AOF 설정 off
● 특정 commands disable
○ Keys
○ AWS의 ElasticCache는 이미 하고 있음.
● 전체 장애의 90% 이상이 KEYS와 SAVE 설정을 사용해서
발생.
ex) SAVE 설정: 1분안에 key 1만개 바뀌면 메모리 덤프해
● 적절한 ziplist 설정
Redis 데이터 분산
데이터의 특성에 따라서 선택할 수 있는 방법이 달라짐
Cache 일때는 우아한 Redis
Persistent 해야하면 안 우하나 Redis
데이터 분산 방법
● Application
1)Consistent Hashing - twemproxy를 사용하는 방법으로 쉽게 사용가능
그냥 서버대수로인한 모듈러 쓰면 서버 추가 삭제에 따른 리밸런싱이 심하게 난다.
해싱을 해서 자기값보다 큰데 가장 가까운 서버로 이동.없으면 원으로 돌아가서 제일 앞에있는 서버로( 서버 변동시 그 서버의 것만 이동시킴)
2)Sharding
데이터를 어떻게 나눌 것인가?
데이터를 어떻게 찾을 것인가?
하나의 데이터를 모든 서버에서 찾아야 하면?
상황마다 샤딩 전략이 달라짐
가장 쉬운건 Range : 특정 range를 정의하고 해당 range에 속하면 거기에 저장 1~1000/ 1001~2000/2001~3000
확장능력은 좋으나 놀고있는 서버,열일서버 있음.
모듈러를 동일하게 사용하는데 서버를 2배로 추가하는 방식으로 바꾸면..
서버 2개->4개->8대
추가되는 데이터를 모듈러2개->4개->8개로 나눈다.(반이 넘어감)
문제는 8->16->32
indexed
해당 key가 어디에 저장되어야 할 관리 서버가 따로 존재.
인덱스 서버 죽으면 장애
Redis Cluster
Hash 기반으로 Slot 16384 로 구분
○ Hash 알고리즘은 CRC16을 사용
○ Slot = crc16(key) % 16384
○ Key가 Key{hashkey} 패턴이면 실제 crc16에
hashkey가 사용된다.
○ 특정 Redis 서버는 이 slot range를 가지고 있고, 데이터
migration은 이 slot 단위의 데이터를 다른 서버로
전달하게 된다.(migrateCommand 이용)
Redis Cluster의 장점/단점
● 장점
○ 자체적인 Primary, Secondary Failover.
○ Slot 단위의 데이터 관리.
● 단점
○ 메모리 사용량이 더 많음
○ Migration 자체는 관리자가 시점을 결정해야 함.
○ Library 구현이 필요함.
Redis Failover
● Coordinator 기반 Failover
● VIP(virtual IP)/DNS 기반 Failover
● Redis Cluster 의 사용
Coordinator 기반
● Coordinator 기반으로 설정을 관리한다면 동일한 방식으로
관리가 가능.
● 해당 기능을 이용하도록 개발이 필요하다.
VIP/DNS 기반
● 클라이언트에 추가적인 구현이 필요없다.
● VIP 기반은 외부로 서비스를 제공해야 하는 서비스 업자에 유리
(예를 들어 클라우드 업체)
● DNS 기반은 DNS Cache TTL을 관리해야 함.
○ 사용하는 언어별 DNS 캐싱 정책을 잘 알아야 함
○ 툴에 따라서 한번 가져온 DNS 정보를 다시 호출 하지 않는
경우도 존재
Monitoring Factor
● Redis Info를 통한 정보
○ RSS (OS 피지컬 메모리를 얼마나 사용하나?)
○ Used Memory(레디스 자신이 쓰고있는 메모리)
○ Connection 수
○ 초당 처리 요청 수
● System
○ CPU
○ Disk
○ Network rx/tx
CPU가 100%를 칠 경우
● 처리량이 매우 많다면?
○ 좀 더 CPU 성능이 좋은 서버로 이전
○ 실제 CPU 성능에 영향을 받음
■ 그러나 단순 get/set은 초당 10만 이상 처리가능
● O(N) 계열의 특정 명령이 많은 경우.
○ Monitor 명령을 통해 특정 패턴을 파악하는 것이 필요
○ Monitor 잘못쓰면 부하로 해당 서버에 더 큰 문제를
일으킬 수도 있음.(짧게 쓰는게 좋음)
결론
● 기본적으로 Redis는 매우 좋은 툴
● 그러나 메모리를 빡빡하게 쓸 경우, 관리하기가 어려움
○ 32기가 장비라면 24기가 이상 사용하면 장비 증설을
고려하는 것이 좋음.
○ Write가 Heavy 할 때는 migration도 매우 주의해야함.
● Client-output-buffer-limit 설정이 필요.
Redis as Cache
● Cache 일 경우는 문제가 적게 발생
○ Redis 가 문제가 있을 때 DB등의 부하가 어느정도
증가하는 지 확인 필요.
○ Consistent Hashing도 실제 부하를 아주 균등하게
나누지는 않음. Adaptive Consistent Hashing 을
이용해 볼 수도 있음.
Redis as Persistent Store
● Persistent Store의 경우
○ 무조건 Primary/Secondary 구조로 구성이 필요함
○ 메모리를 절대로 빡빡하게 사용하면 안됨.
■ 정기적인 migration이 필요.
■ 가능하면 자동화 툴 을 만들어서 이용
○ RDB/AOF가 필요하다면 Secondary에서만 구동