
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- JPA
- Linux
- #docker compose
- 친절한 SQL 튜닝
- 리눅스
- @Transactional Propagation
- 자바 ORM 표준 JPA 프로그래밍 정리
- ksqldb
- 리팩토링 2판
- java
- intellij 즐겨찾기
- 원격 브랜 삭제
- intellij 핵심 단축키
- findTopBy
- vue.js
- Spring Cloud Netflix
- IntelliJ
- 자바 ORM 표준 JPA 프로그래밍
- intellij favorites
- multipart테스트
- aws
- @TransactionalEventListener
- CompletableFuture
- javascript case
- 백명석님
- git
- Stream
- ksql
- HandlerMethodArgumentResolver
- 마이크로 서비스
- Today
- Total
시그마 삽질==six 시그마
kafka stream 본문
카프카 스트림즈: 토픽에 적재된 데이터를 실시간으로 변환하여 다른 토픽에 적재하는 라이브러리다.
Database에 저장 후 분석 및 처리하는 것이 아니라,Kafka에 있는 움직이는 데이터(Data in Motion)를 바로 분석 및 처리하는 것이 핵심! 실시간 이벤트 스트림을 실시간으로 분석하여, 실시간으로 빠르게 대응하기 위한 기술
Java 및 Scala로 실시간 이벤트 스트리밍 처리용 애플리케이션 및 마이크로 서비스를 작성하기 위한 Apache Kafka® Streams 라이브러리

기존 카프카 pub/sub에 비해 코드 간결화!! ->ksqlDB 사용시 더욱 간결화!!(sql!!)
(KStream, KTable) → KStream
KStream & KStream -> only window

*소스토픽과 싱크토픽의 카프카 클러스터가 서로 다른 경우는 스트림즈가 지원하지 않으므로 이때는 컨슈머와 프로듀서 조합으로 직접
클러스터를 지정하는 방식으로 개발할 수 있다.
스트림즈 애플리케이션은 내부적으로 스레드를 1개 이상 생성가능
스레드는 1개 이상의 테스크를 가짐. 스트림즈의 태스크는 스트림즈 애플리케이션을 실행하면 생기는 데이터 처리 최소단위
3개파티션의 토픽 처리하는 스트림즈 애플리케이션 실행시 내부에 3개의 테스크생김.(컨슈머그룹 컨슈머 스레드 병렬처리와 비슷)
스트림즈 애플리케이션은 카프카 클러스터와 커뮤니케이트 한다.
소스 프로세서: (데이터를 처리하기위해 최초로 선언해야하는 노드로) 하나 이상의 토픽에서 데이터 가져오는 역할 (컨슘 하듯)
stream(), .table(), gloabalTable() 메서드들은 최초의 토픽 데이터를 가져오는 소스 프로세서이다.
스트림 프로세서: 다른 프로세서가 반환한 데이터를 처리(변환,분기처리)하는 역할( 토픽끼리 조인도 가능)
싱크 프로세서: 데이터를 특정 카프카 토픽으로 저장하는 역할을 한다.(프로듀서 하듯)
to()메서드는 싱크 프로세서이다.
스트림즈 DSL과 프로세서 API 2가지 방법으로 개발 가능함.
스트림즈 DSL에는 레코드의 흐름을 추상화한 3가지 개념인 KStream, KTable,GlobalKTable이 있음.
프로세서 API 방법은 KStream, KTable,GlobalKTable 개념없음. 스트림 프로세서는 클래스 새로 만들어야함
스트림즈 DSL로 구현하는 데이터 처리 예시
* 메시지 값을 기반으로 토픽 분기처리
* 지난 10분간 들어온 데이터의 개수 집계
* 토픽과 다른 토픽의 결합으로 새로운 데이터 생성
프로세서 API로 구현하는 데이터 처리 예시
*메시지 값의 종류에 따라 토픽을 가변적으로 전송
*일정한 시간 간격으로 데이터 처리
KStream(Stateless)
KStream은 레코드의 흐름을 표현. 메시지 키와 메시지값으로 구성.
KStream은 토픽의 모든 레코드 조회 가능(토픽에 존재하는 데이터의 key의 중복을 허용)
All inserts, similar to a log, infinte, Unbounded data streams
KStream reading from a topic that's not compacted
KStream if new data is partial information/transactional
KTable(stateful)
KTable은 KStream과 다르게 메시지 키를 기준으로 묶어서 사용
KTable은 유니크한 메시지 키를 기준으로 가장 최근 레코드를 사용(데이터의 key의 중복을 허용하지 않고 가장 최신에 넣어진 key의 값으로 덮어씀)
KStream과 KTable을 조인하려면 반드시 코파티셔닝 되있어야함. 이럴 경우 동일한 메시지키를 가진 데이터가 동일한 태스크에 들어가는것을 보장
All upserts on non null values, deletes on null values, Similar to a table, parallel with log compacted topics
KTable more if you need a structure that's like a database table where every update is self sufficient (think-total bank balance)


코파티셔닝
조인 하는 2개 데이터의 파티션 개수가 동일 & 파티셔닝 전략을 동일하게 맞추는 작업
파티션 개수가 동일하고 파티션닝 전략이 같은 경우에는 동일한 메시지 키를 가진 데이터가 동일한 테스크에 들어가는 것을 보장하기에
이를 통해 각 테스크는 KStream의 레코드와 KTable의 메시지 키가 동일한 경우 조인을 수행할 수 있음.
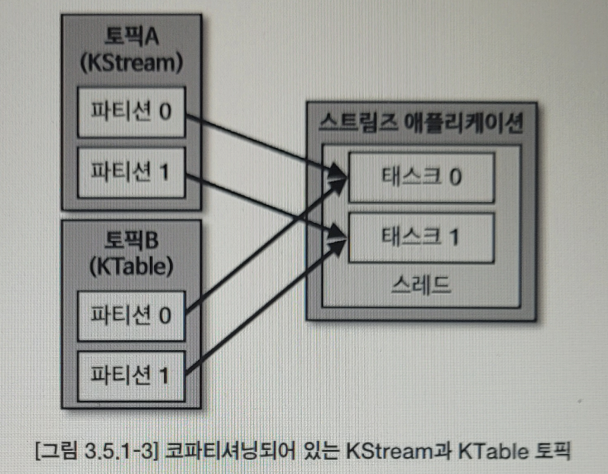
리파티셔닝:
Kstream과 KTable로 사용하는 2개의 토픽이 파티션 개수가 다를 수 있고 파티션 전략이 다를 수 있다. 이런경우 조인을 수행할 수 없다. 코파티셔닝 되지 않는 2개의 토픽을 조인하는 로직 담긴 스트림 애플리케이션 실행시 TopologyException이 발생한다.
조인을 수행하는 Kstream과 KTable이 코파티셔닝 되어 있지 않으면 Kstream 또는 KTable을 리파티셔닝 하는과정을 거쳐야한다
새로운 토픽에 새로운 메시지 키를 가지도록 재배열하는 과정

GlobalKTable
GlobalKTable은 KTable과 동일하게 메시지 키를 기준으로 묶어서 사용된다.
KTable로 선언된 토픽은 1개 파티션이 1개 테스크에할당되 사용되고
GlobalKTable로 선언된 토픽은 모든 파티션 데이터가 각각의 테스크에 할당되어(모든 파티션의 데이터가 테스크1,테스크2,테스크3..에 똑같이 들어감) 사용된다는 차이점 있음.
코파티셔닝 되어 있지 않은 2개의 토픽을 조인하기 위해서는 항상 리파티셔닝 방법외 KTable을 GlobalKTable로 선언하여 사용하는 방법도 있음. GlobalKTable은 코파티셔닝되지 않은 KStream과 데이터 조인을 할 수 있음. 왜냐하면 KTable과 다르게 GlobalKTable로 정의된 데이터는 스트림즈 애플리케이션의 모든 테스크에 동일하게 공유되어 사용되기 때문.
다만, GlobalKtable을 사용하면 각 테스크마다 GlobalKtable로 정의된 모든 데이터를 저장하고 사용하기 때문에 로컬 스토리지의 사용량이 증가하고 네트크,브로커에 부하가 생기므로 작은용량의 데이터일 경우만 사용하는것이 좋음.

코파티셔닝 필요없는 경우 2가지
Co-partitioning is not required when performing 1) KTable-KTable Foreign-Key joins and 2)Global KTable joins.
https://kafka.apache.org/24/documentation/streams/developer-guide/dsl-api.html
코파티셔닝 안되있는 데이터 조인 방법2가지
1)리파티셔닝해야 조인가능
2)리파티셔닝 없이 조인원할시 KTable을 GlobalKTable로 선언하면됨(단, 로컬스토리지 사용량증가,네트워크,브로커 부하로 작은 용량만 할것)
kafka streams 옵션
https://kafka.apache.org/21/documentation/streams/developer-guide/config-streams.html
https://docs.confluent.io/platform/current/installation/configuration/streams-configs.html
Streams 필수 옵션(java code)
bootstrap.servers: 프로듀서 데이터를 전송할 대상 카프카 클러스터에 소한 브로커의 호스트이름:포트1 개이상 작성.
application.id: 스트림즈 애플리케이션을 구분하기 위한 고유한 아이디를 설정한다. 다른 로직을 가진 스트림즈 애플리케이션은 서로 다른 application.id값을 가져야한다
Streams 선택 옵션(java code)
default.key.serde: 레코드의 메시지 키를 직렬화,역직렬화하는 클래스 지정한다. 기본값은 serdes.ByteArray().getClass().getName()이다.
default.value.serde: 레코드의 메시지 값을 직렬화,역직렬화하는 클래스 지정한다. 기본값은 serdes.ByteArray().getClass().getName()이다.
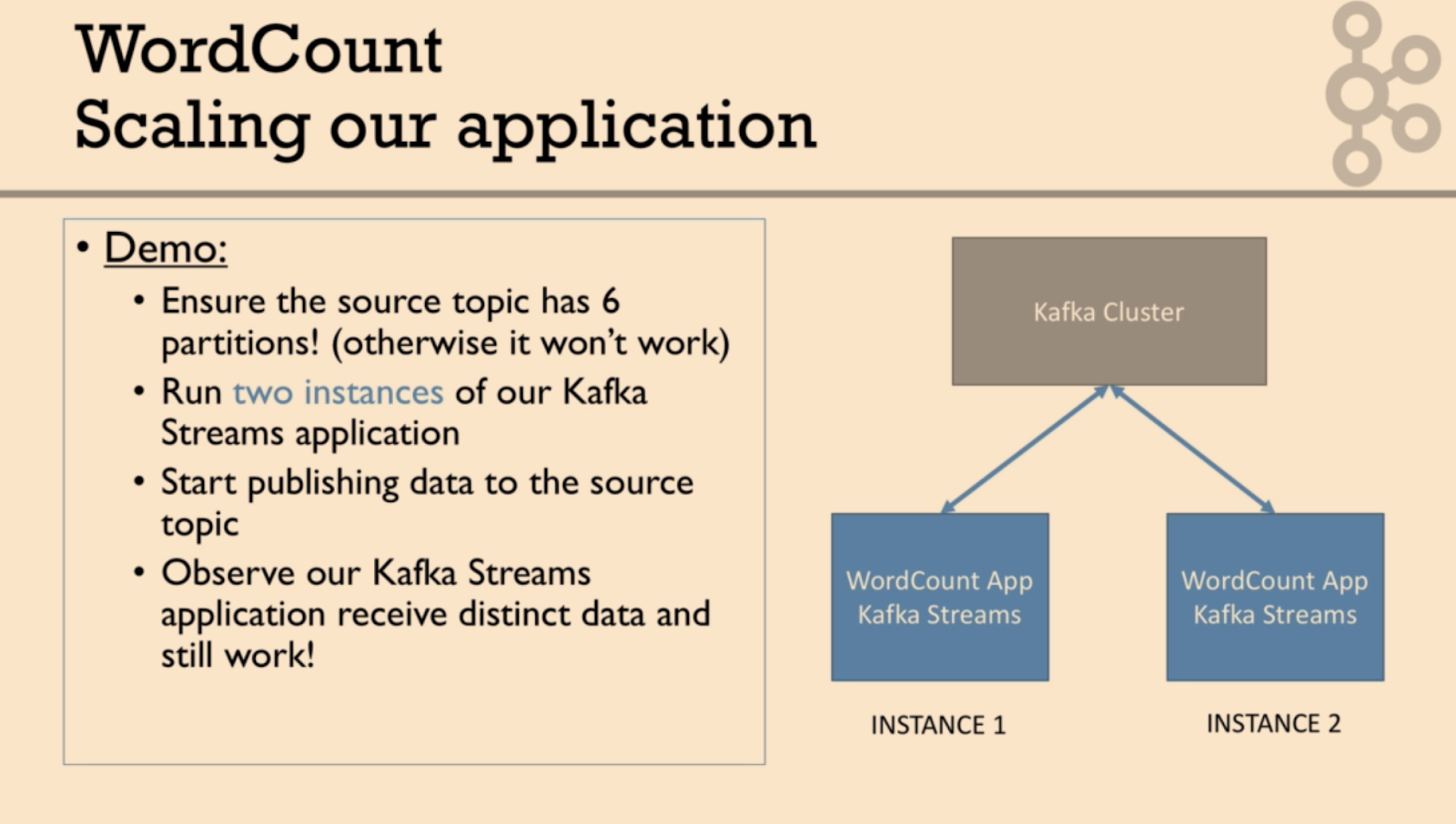
num.stream.threads: 스트림프로세스 실행시 실행될 스레드 개수를 지정. 기본값은 1
The number of threads to execute stream processing.
Type: int
Default: 1
Valid Values:
Importance: medium
Your streams application is reading from an input topic that has 5 partitions. You run 5
instances of your application, each with num.streams.threads set to 5. How many stream tasks will
be created and how many will be active? 25 created, 5 active
num.standby.replicas <---0 이상해야 fault tolerance
The number of standby replicas for each task.
Type: int
Default: 0
Valid Values:
Importance: high
state.dir: 상태기반 데이터 처리를 저장할때 데이터를 저장할 디렉토리를 지정한다. 기본값은 /tmp/kafka-streams다
Directory location for state store. This path must be unique for each streams instance sharing the same underlying filesystem.
Type: string
Default: /tmp/kafka-streams
Valid Values:
Importance: high
https://stackoverflow.com/questions/55104527/why-kafka-streams-state-dir-is-in-tmp-kafka-streams
processing.guarantee:
The processing mode. Can be either at_least_once (default), or exactly_once_v2 (for EOS version 2, requires Confluent Platform version 5.5.x / Kafka version 2.5.x or higher). Deprecated config options are exactly_once (for EOS version 1) and exactly_once_beta (for EOS version 2).
https://docs.confluent.io/platform/current/streams/concepts.html
At-least-once semantics is enabled by default (processing.guarantee="at_least_once") in your Streams configuration.
Internal topic(브로커 내부 토픽)
Running a kafka streams may eventually create internal intermediary topics
Two types:
Repartitioning topics: in case start transforming the key of your stream, a repartitioning will happen at some processor
Changelog topics: in case you perform aggregations, kafka Streams will save compacted data in these topics
<--kafka Streams의 상태 저장소가 고장났을때를 대비한 빽업용임!!! 그런 상황발생시 이게 Streams의 상태저장소를 복구해줌.
https://stackoverflow.com/questions/65041551/what-are-the-consumers-for-state-store-changelog-topics
https://developer.confluent.io/learn-kafka/kafka-streams/stateful-fault-tolerance/
Internal topics:
Are managed by kafka Streams
Are used by kafka Streams to save /restore state and re-partition data
are prefixed by application.id parameter
should never be deleted, altered or published to.
<application.id>-<operatorName>-<suffix>
wordcount-application-Counts-changelog
wordcount-application-Counts-repartition
https://docs.confluent.io/platform/current/streams/developer-guide/manage-topics.html



StreamBuilder는 Stream(),Table(),GlobalTable()<---k빠짐!!! 메서드 지원한다
to()메소드는 Kstream 인스턴스의 데이터들을 특정 토픽으로 저장하기위한 용도로 사용되나. 즉 to() 메서드는 싱크 프로세서이다.
public class KStreamJoinKTable {
private static String APPLICATION_NAME = "order-join-application";
private static String BOOTSTRAP_SERVERS = "my-kafka:9092";
private static String ADDRESS_TABLE = "address";
private static String ORDER_STREAM = "order";
private static String ORDER_JOIN_STREAM = "order_join";
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KTable<String, String> addressTable = builder.table(ADDRESS_TABLE);
KStream<String, String> orderStream = builder.stream(ORDER_STREAM);
orderStream.join(addressTable, (order, address) -> order + " send to " + address).to(ORDER_JOIN_STREAM);
KafkaStreams streams;
streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
//
//
//./kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic address --property "parse.key=true" --property "key.separator=:"
// >wonyoung:Seoul
// >somin:Newyork
// >wonyoung:Seoul
// >somin:Newyork
//
// ./kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic order --property "parse.key=true" --property "key.separator=:"
// >somin:cup
// >somin:cup
// >wonyoung:iPhone
//
// ./kafka-console-consumer.sh --bootstrap-server my-kafka:9092 --topic order_join --from-beginning
// cup send to Newyork
// cup send to Newyork
// cup send to Newyork
// iPhone send to Busan
//
public class KStreamJoinGlobalKTable {
private static String APPLICATION_NAME = "global-table-join-application";
private static String BOOTSTRAP_SERVERS = "my-kafka:9092";
private static String ADDRESS_GLOBAL_TABLE = "address_v2";
private static String ORDER_STREAM = "order";
private static String ORDER_JOIN_STREAM = "order_join";
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
GlobalKTable<String, String> addressGlobalTable = builder.globalTable(ADDRESS_GLOBAL_TABLE);
KStream<String, String> orderStream = builder.stream(ORDER_STREAM);
orderStream.join(addressGlobalTable,
(orderKey, orderValue) -> orderKey,
(order, address) -> order + " send to " + address)
.to(ORDER_JOIN_STREAM);
KafkaStreams streams;
streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
//
// ./kafka-topics.sh --bootstrap-server my-kafka:9092 --create --partitions 2 --topic address_v2
// WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
// Created topic address_v2.
//
//
//
// ./kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic address_v2 --property "parse.key=true" --property "key.separator=:"
// >wonyoung:Jeju
//
//
//./kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic address --property "parse.key=true" --property "key.separator=:"
// >wonyoung:Seoul
// >somin:Busan
//
// ./kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic order --property "parse.key=true" --property "key.separator=:"
// >somin:Porche
// >wonyoung:BMW
//
// ./kafka-console-consumer.sh --bootstrap-server my-kafka:9092 --topic order_join --from-beginning
// samin:Porche send to Busan
// Wonyoung: BMW send to Seoul
//
프로세서 API





addSource()
addProcessor()
addSink()
public class SimpleKafkaProcessor {
private static String APPLICATION_NAME = "processor-application";
private static String BOOTSTRAP_SERVERS = "my-kafka:9092";
private static String STREAM_LOG = "stream_log";
private static String STREAM_LOG_FILTER = "stream_log_filter";
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
Topology topology = new Topology();
topology.addSource("Source",
STREAM_LOG)
.addProcessor("Process",
() -> new FilterProcessor(),
"Source")
.addSink("Sink",
STREAM_LOG_FILTER,
"Process");
KafkaStreams streaming = new KafkaStreams(topology, props);
streaming.start();
}
}
public class FilterProcessor implements Processor<String, String> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(String key, String value) {
if (value.length() > 5) {
context.forward(key, value);
}
context.commit();
}
@Override
public void close() {
}
}
//https://kafka.apache.org/documentation/streams/developer-guide/processor-api.html

Available stateful transformations in the DSL include:
Aggregating
aggregate
count
reduce
Joining
Windowing (as part of aggregations and joins)
ACR jw























KStream-KStream join: window join
https://docs.confluent.io/platform/current/streams/developer-guide/dsl-api.html#joining
- 호핑 윈도우 : 고정적인 사이즈의 윈도우, 윈도우끼리 겹치는 부분이 있음


import java.time.Duration;
import org.apache.kafka.streams.kstream.TimeWindows;
// A hopping time window with a size of 5 minutes and an advance interval of 1 minute.
// The window's name -- the string parameter -- is used to e.g. name the backing state store.
Duration windowSizeMs = Duration.ofMinutes(5);
Duration advanceMs = Duration.ofMinutes(1);
TimeWindows.of(windowSizeMs).advanceBy(advanceMs);
0분~5분 -> 1분 ~6분 -> 2분 ~7분….
https://kafka.apache.org/28/documentation/streams/developer-guide/dsl-api.html#windowing
https://kafka.apache.org/28/documentation/streams/developer-guide/dsl-api.html#windowing-hopping
- 텀블링 윈도우 : 고정적인 사이즈의 윈도우, 윈도우끼리 겹치는 부분이 없음



import java.time.Duration;
import org.apache.kafka.streams.kstream.TimeWindows;
// A tumbling time window with a size of 5 minutes (and, by definition, an implicit
// advance interval of 5 minutes). Note the explicit grace period, as the current
// default value is 24 hours, which may be larger than needed for smaller windows.
Duration windowSizeMs = Duration.ofMinutes(5);
Duration gracePeriodMs = Duration.ofMinutes(1);
TimeWindows.of(windowSizeMs).grace(gracePeriodMs);
// The above is equivalent to the following code:
TimeWindows.of(windowSizeMs).advanceBy(windowSizeMs).grace(gracePeriodMs);
0~5초→ 5초~10초
https://blog.voidmainvoid.net/452
https://kafka.apache.org/28/documentation/streams/developer-guide/dsl-api.html#windowing-tumbling
텀블링 윈도우를 구현하는 스트림즈DSL코드는 다음과 같습니다.
KStream<String, String> userClickStream = ..;
KTable<Windowed<String>, Long> userClickWindowTable = userClickStream
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(5)))
.count();
사용자의 클릭을 스트림으로 받은 뒤 5초마다 텀블링 윈도우를 통해 데이터를 추출하는 코드입니다. 당연하게도 유저의 정보를 취합하기 위해서는 레코드의 메시지 키를 유저 정보(유저 키)로 사용해야 합니다. 우리가 생각대로 코드가 동작한다고 가정한다면 아래와 같은 input과 output이 나와야 합니다.
input
1초 : A
2초 : A
4초 : A,B
6초 : A
7초 : A
output
5초 : (A,3),(B,1)
10초 : (A,2)
그런데 하단과같이 다른 결과가 나오는 이유는 commit interval에 따라 다른데요. commit interval이 3초 인 경우에는 다음과 같은 output이 추출됩니다.
output
3초 : (A,2 - 0초~5초)
6초 : (A,3 - 0초~5초), (A,1 - 6초~10초), (B,1 - 0초~5초)
9초 : (A,2 - 6초~10초)
각 텀블링 윈도우는 겹치지 않았습니다. 다만, 동일한 윈도우의 결과가 커밋 타이밍때 한번 더 추출된 것을 볼 수 있습니다.
사용자가 원하는 값은 각 윈도우의 마지막 값을 따로 추출해야합니다. 진짜로 원하는 가장 마지막 윈도우 처리는 bold로 표시한 아래 데이터 일것입니다.
우리가 진짜로 원하는 데이터를 얻기 위해 어떻게 해야할까요? 방법은 두가지입니다.
방법1) 윈도우 타임을 포함한 데이터를 사용하여 idemoptence 동작하도록 설정
동일 window시간이 포함된 데이터가 처음에 한번 그리고 나중에 한번 들어왔을 때 나중의 데이터를 넣는 방식입니다.
방법2) suppress() 사용
커밋타이밍과 무관하게 윈도우가 끝날 때 또는 메모리에 데이터가 가득 찼을 때 마지막의 윈도우 연산을 추출하는 것인데요. 현재 잘 안된다함.
- 슬라이딩 윈도우 : 고정적인 사이즈의 윈도우, 레코드의 timestamp값에 따라 window가 겹칠 수도 안겹칠 수도 있음
SlidingWindow는 window종류 중 하나로서 일정 시간동안의 데이터들의 집합에 대해 연산을 하는 것을 뜻합니다.
이벤트에 따라 윈도우 결정됨
https://stackoverflow.com/questions/43188997/hopping-vs-sliding-window
Microsoft has a good explanation (link). Basically, a hopping window always advances by a specific time interval from the start of the time series. A sliding window only advances when there is data in the time series to evaluate.
Dataset:
- Time T: 18
- T+1: 12
- T+7: 20
- T+11: 15
- T+16: 19
- T+27: 107
Hopping: Starting at time T, sum values for 10 second window, advance by 5 seconds
- T-T10: 50 (18+12+20)
- T5-T15: 35 (20+15)
- T10-T20: 24 (15+19)
- T15-T25: 19 (19)
- T20-T30: 107
Sliding: Starting at time T, sum values for 10 second windows
- T: 50 (18+12+20)
- T1: 47 (12+20+15)
- T7: 44 (20+15+19)
- T11: 24 (15+19)
- T16: 19 (19)
- T27: 107 (107)
The Hopping window is more schedule based, producing output on every period for exactly that period. The Streaming window is more event based, producing output only when data is present.
https://blog.voidmainvoid.net/446
https://kafka.apache.org/28/documentation/streams/developer-guide/dsl-api.html#windowing-sliding
https://stackoverflow.com/questions/43188997/hopping-vs-sliding-window
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
import org.apache.kafka.streams.kstream.SlidingWindows;
// A sliding time window with a time difference of 10 minutes and grace period of 30 minutes
Duration timeDifferenceMs = Duration.ofMinutes(10);
Duration gracePeriodMs = Duration.ofMinutes(30);
SlidingWindows.withTimeDifferenceAndGrace(timeDifferenceMs,gracePeriodMs);
주의해야할 점은 윈도우에 속한 레코드의 개수가 달라지는 경우에만 윈도우 연산이 발동
다음과 같은 레코드가 있을 경우를 예로 들 수 있습니다.
(timeDifferenceMs = 5000ms)
이 경우 아래와 같이 5번의 연산이 일어납니다.

- window [3000;8000] contains [1] (created when first record enters the window)
- window [4200;9200] contains [1,2] (created when second record enters the window)
- window [7400;12400] contains [1,2,3] (created when third record enters the window)
- window [8001;13001] contains [2,3] (created when the first record drops out of the window)
- window [9201;14201] contains [3] (created when the second record drops out of the window)
- timeDifferenceMs : 서로 다른 두개의 레코드가 동일 윈도우에 들어가기 위한 최대 시간 간격
- gracePeriodMs : 레코드간에 timestamp의 순서를 허용하기 위한 시간 (The grace period to admit out-of-order events to a window.)
이 중 gace period의 동작은 독특한데요. 윈도우에서 레코드가 무조건 순서가 완벽하게 보장하지 않을 수 없습니다. 프로듀서가 여러개이고 파티션이 여러개인 이상 동일한 메시지 키라도 timestamp의 순서가 변경될 수 있습니다. 그래서 서로 다른 레코드 간의 timestamp가 일부 차이가 나더라도 허용을 하기 위해 사용됩니다.
- 세션 윈도우 : 윈도우 사이즈가 동적으로 변경됨. 데이터기반 윈도우
추가적으로 suppress()라고 불리는 윈도우 종료 연산도 지원합니다. 윈도우 종료 연산은 윈도우가 종료될 때 결괏값을 주는 데에 목적이 있습니다.


https://kafka.apache.org/28/documentation/streams/developer-guide/dsl-api.html#windowing-session
호핑윈도우
public class StreamsWindows {
public static void main(String[] args) throws IOException {
final Properties streamsProps = StreamsUtils.loadProperties();
streamsProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "windowed-streams");
StreamsBuilder builder = new StreamsBuilder();
final String inputTopic = streamsProps.getProperty("windowed.input.topic");
final String outputTopic = streamsProps.getProperty("windowed.output.topic");
final Map<String, Object> configMap = StreamsUtils.propertiesToMap(streamsProps);
final SpecificAvroSerde<ElectronicOrder> electronicSerde =
StreamsUtils.getSpecificAvroSerde(configMap);
final KStream<String, ElectronicOrder> electronicStream =
builder.stream(inputTopic, Consumed.with(Serdes.String(), electronicSerde))
.peek((key, value) -> System.out.println("Incoming record - key " +key +" value " + value));
electronicStream.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofHours(1)).grace(Duration.ofMinutes(5)))
.aggregate(() -> 0.0,
(key, order, total) -> total + order.getPrice(),
Materialized.with(Serdes.String(), Serdes.Double()))
.suppress(untilWindowCloses(unbounded()))
.toStream()
.map((wk, value) -> KeyValue.pair(wk.key(),value))
.peek((key, value) -> System.out.println("Outgoing record - key " +key +" value " + value))
.to(outputTopic, Produced.with(Serdes.String(), Serdes.Double()));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsProps);
TopicLoader.runProducer();
kafkaStreams.start();
}
}
kafka streams exactly-once semantics
https://kafka.apache.org/32/documentation/streams/core-concepts
Since the 0.11.0.0 release, Kafka has added support to allow its producers to send messages to different topic partitions in a transactional and idempotent manner, and Kafka Streams has hence added the end-to-end exactly-once processing semantics by leveraging these features. More specifically, it guarantees that for any record read from the source Kafka topics, its processing results will be reflected exactly once in the output Kafka topic as well as in the state stores for stateful operations.
As of the 2.6.0 release, Kafka Streams supports an improved implementation of exactly-once processing, named "exactly-once v2", which requires broker version 2.5.0 or newer. As of the 3.0.0 release, the first version of exactly-once has been deprecated.
To enable exactly-once semantics when running Kafka Streams applications, set the processing.guarantee config value (default value is at_least_once) to StreamsConfig.EXACTLY_ONCE_V2 (requires brokers version 2.5 or newer).
======================================================================
Local State Stores
Kafka Streams provides so-called state stores, which can be used by stream processing applications to store and query data, which is an important capability when implementing stateful operations. The Kafka Streams DSL, for example, automatically creates and manages such state stores when you are calling stateful operators such as join() or aggregate(), or when you are windowing a stream.
Every stream task in a Kafka Streams application may embed one or more local state stores that can be accessed via APIs to store and query data required for processing. Kafka Streams offers fault-tolerance and automatic recovery for such local state stores.
The following diagram shows two stream tasks with their dedicated local state stores.
https://kafka.apache.org/32/documentation/streams/architecture
Kafka Streams는 데이터를 저장하고 쿼리하기 위해 스트림 처리 응용 프로그램에서 사용할 수 있는 소위 상태 저장소 를 제공합니다. 이는 상태 저장 작업을 구현할 때 중요한 기능입니다. 예를 들어 Kafka Streams DSL 은 join()또는 와 같은 상태 저장 연산자를 호출 aggregate()할 때 또는 스트림을 윈도우화할 때 이러한 상태 저장소를 자동으로 만들고 관리 합니다.
Kafka Streams 애플리케이션의 모든 스트림 작업에는 처리에 필요한 데이터를 저장하고 쿼리하기 위해 API를 통해 액세스할 수 있는 하나 이상의 로컬 상태 저장소가 포함될 수 있습니다. Kafka Streams는 이러한 로컬 상태 저장소에 대한 내결함성 및 자동 복구를 제공합니다.
-local state store
persistent rocks DB store
in memory store
custom user_defined store
https://developer.confluent.io/learn-kafka/kafka-streams/stateful-fault-tolerance/
기존에 사용하던 Realtime Event Stream Processing 방법들 Apache Spark, Storm, Flink
Apache Spark
• UC버클리대학교에서 개발(2009, 2010 BSD, 2013 ASF)
• 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 프레임워크
• MapReduce 형태의 클러스터 컴퓨팅 패러다임의 한계를 극복하고자 등장
• Spark Cluster를 구성해야 하며 이를 관리하는 Cluster Manager와 데이터를
분산 저장하는 Distributed Storage System이 필요 - 사용이 어려움
Apache Storm
• 2011년에 개발된 후 트위터(Twitter, Inc.)에 의해 오픈소스화(2014)
• 주로 Clojure 프로그래밍 언어로 작성된 분산형 스트림 프로세싱 프레임워크
• 별도의 Storm Cluster를 설치 구성
• 상태 관리가 지원되지 않아 Aggregation, Windows, Water Mark 등을 사용할
수없기때문에고급분석에제약
Apache Flink
• 베를린 TU대학교에서 시작(2010, 2014 오픈소스화)
• 통합 스트림 처리 및 Batch 처리 프레임워크
• Java 및 Scala로 작성된 분산 스트리밍 Data Flow 엔진
• 사용자의 Stream Processing Code는 Flink Cluster에서 하나의 Job으로
배포및실행
Kafka Streams
• Event Streaming용 Library(Java, Scala)
• Kafka 0.10.0.0 에 처음 포함(2016)
• Framework 이 아님 - 별도의 Cluster 구축이 불필요
• application.id 로 KStreams Application을 grouping(컨슈머 그룹핑하듯)
• groupBy, count, filter, join, aggregate 등 손쉬운 스트림 프로세싱 API 제공
Java 및 Scala로 실시간 이벤트 스트리밍 처리용 애플리케이션 및 마이크로 서비스를 작성하기 위한 Apache Kafka® Streams 라이브러리
Java 및 Scala로 코드 작성<--->재컴파일 후 애플리케이션 실행/ 테스트
ksqlDB
sql을 사용하여 실시간 이벤트 스트리밍 처리용 애플리케이션 작성하기위한 스트리밍DB(sql엔진)
• Event Streaming Database(또는 SQL 엔진) -RDBMS/NoSQL DB 가 아님
• Confluent Community License(2017)
• 간단한 Cluster 구축 방법 - 동일한 ksql.service.id 로 ksqlDB를 여러 개 기동
• 여러 개의 Cluster는 ksql.service.id 값을 서로 다르게 하기만 하면 됨
• SQL과 유사한 형태로 ksqlDB에 명령어를 전송하여 스트림 프로세싱 수행

if you ever lose a machine with the state store
active node goes down
참고
카프카 스트림 강의 : https://developer.confluent.io/learn-kafka/kafka-streams/get-started/
https://github.com/confluentinc/learn-kafka-courses.git
'프로그래밍 > Kafka' 카테고리의 다른 글
| kafka schema registry (0) | 2022.08.26 |
|---|---|
| kafka ksqlDB (0) | 2022.08.26 |
| kafka connect (0) | 2022.08.25 |
| kafka 모니터링 (0) | 2022.08.01 |
| kafka 전략 (0) | 2022.07.31 |



